His expectations around producing documentation go only as far as "Think about what documentation or data users need to understand and use your solution."
That seems like rather a low bar, compared to items like "I can articulate how all the data I use is laid out in memory."
I'd prefer to live in a world where a professional software engineer was expected to write documentation, and expected to be competent at it.
> I can articulate how all the data I use is laid out in memory.
That's not a high bar, it's an arbitrary hoop. It'd be like saying "I always know which processor cache my variables are sitting in". In modern languages it may be literally impossible to look at a block of code and know what's sitting in the heap vs. on the stack, and the heap is often broken into many different components only fully understood by the compiler/interpreter/VM writers. We want to abdicate responsibility of this kind of memory management to the interpreter, just like we want to abdicate responsibility for handling processor cache levels. If you can articulate how all the data you use is laid out in memory all the time, you are majorly micro-managing the runtime.
Not sure if you're familiar with Mike Acton (as mentioned in the article). One of his key points of focus is data-oriented design, and that when designing software, ignoring the architectural realities of the hardware is ignoring one of your responsibilities as an engineer to deliver performant software.
Now, it's possible to argue that writing performant software is not important. The prevailing modern sentiment definitely seems to be "The compiler / interpreter takes care of that". But given his track record of delivering high performant running software, and the trend in computing towards sluggishness, I'm trending more and more towards his camp, than the "don't micro-manage the runtime" camp (which is starting to feel more and more like a thinly-veiled "I don't want to have to think about it").
I don't think it's thinly veiled at all. Some people might be deluding themselves into thinking they aren't losing something by abstracting away the intricacies of the runtime but I imagine most are actively thinking they are okay with this tradeoff. Instead they are allowed to focus more on the domain problems and let their users tell them when it gets to be too slow. Whether it's the right trade off probably depends on what their goals are.
> Now, it's possible to argue that writing performant software is not important.
The quote I'm arguing against is "I can articulate how all the data I use is laid out in memory." Indeed, writing performant code is not important, most of the time. It is critically important a small amount of the time (actual percentages heavily dependent on the type of software), and yes, in those times, understanding the architectural realities of the hardware is somewhere on the list of things you need to understand to do so, just below a solid understanding of complexity analysis, a wide knowledge of useful data structures, proper design of queries and use of indexes (if relevant), etc. A good software engineer does not say "I always know exactly how all my data is laid out in memory", they say "I know when and how to care about that, and the rest of the times I ignore it." Just like they do with many, many other concerns. Anything else is just premature optimization. The most important problem solving skill by far is knowing what you can safely ignore.
> We want to abdicate responsibility of this kind of memory management to the interpreter, just like we want to abdicate responsibility for handling processor cache levels. If you can articulate how all the data you use is laid out in memory all the time, you are majorly micro-managing the runtime.
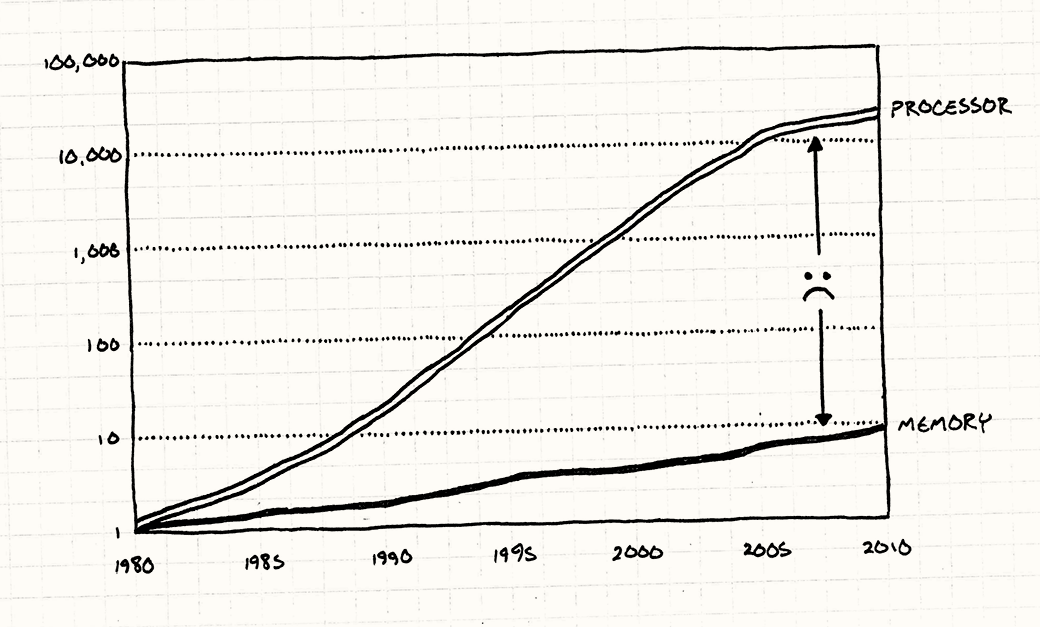
Unfortunately, in practice, it's not possible to be oblivious of the layout of data in memory if we want to write fast code. The CPU/memory speed disparity graph [1] shows the new reality for programmers: the slowest part of a program is bringing data from RAM into the CPU registers. Fortunately, modern CPUs have very fast caches that help amortize this cost and it's the responsibility of the programmer to organize data to take advantage of that fast hardware—the compiler cannot do it. That's why two functions, with the same algorithmic complexity, and which compute the same result, can have an order of magnitude of difference in performance between them [2]. The famed sufficiently smart compiler that can do those transformations does not yet exist as far as I know.
If the slowest part of your program is waiting for RAM to get into your CPU registers, then you have one of the most blazingly fast programs ever written. Grats! The vast majority of software has much, much, much lower-hanging fruit than that: things like O(n^2) algorithms where O(n) exists, SELECT N+1 issues, missing database indexes, missing easy wins with caching, repeated work, threads blocking each other, loading more data than necessary, throwing and then suppressing exceptions everywhere, bad netcode, doing work serially that could be paralyzed, etc. In this software, fixing these issues will be 10x easier and result in 10x larger speedups than worrying about organizing your data to get loaded from RAM into CPU caches more quickly. That makes this advice counterproductive for most programmers to hear.
You want to (I do too!) , but the abstraction eventually leaks (you get unexpected behavior in long running processes because of gc/libc/kernel issues, or you need very specific control performance wise, etc) , and you end up having to know about it.
Knowing how your data is structured in memory is a trivial exercise for anyone working on a game engine like the author of this talk. You don't even need to think about it. The layout of every data structure used by the engine is known and chances are you have implemented a bunch of them yourself.
{kind=link}
That seems like rather a low bar, compared to items like "I can articulate how all the data I use is laid out in memory."
I'd prefer to live in a world where a professional software engineer was expected to write documentation, and expected to be competent at it.