Gingsberg stole it from Yeats — “the best lack all conviction…” / “the best minds of my generation…” — many similar verses, e.g., “what rough beast…” / “what sphinx of cement…”
Those aren't nearly close enough to be considered stolen. Possibly allusions (which is not stealing), but even then, the only similarity of the bests is "The best" usage. Nothing about the rest of the lines, or before, are similar enough to be "stolen" (potentially the Ginsberg troping Yeat's "full of passionate intensity" of the worst into his best's "madness, starving hysterical", but that too is allusion, not stealing).
The best lack all conviction, while the worst //
Are full of passionate intensity.
vs
I saw the best minds of my generation destroyed by madness, starving hysterical naked, //
dragging themselves through the negro streets at dawn looking for an angry fix,
Depending on how comfortable you are with model theory you might also enjoy Dzhafarov and Mummert’s textbook, which first brought the subject to my attention.
This is roughly the intuition I have developed -- any computational function requires time and space to evaluate. Most computations carry with them some epistemic or aleatoric modeling uncertainty, but sometimes even a perfectly deterministic function with a worst case constant time complexity is worth approximating, as the constant factor may be prohibitive.
Given an exact decision procedure with astronomical lower bounds, and an approximate one that is identical on 99.99% of IID sampled inputs that takes a second to evaluate, which would you prefer? Given a low latency, high variance approximation, would you be willing to exchange latency for lower variance? Engineering is all about such tradeoffs.
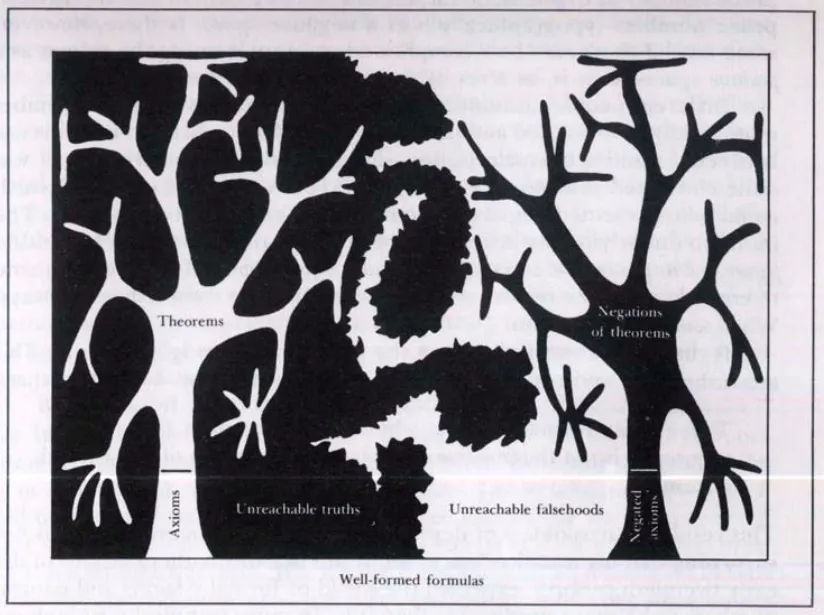
There is a neat picture [1] in GEB that captures a similar idea.
FWIW, I’ve had a very similar encounter with another famous AI influencer who started lecturing me on fake automata theory that any CS undergrad would have picked up on. 140k+ followers, featured on the all the big podcasts (Lex, MLST). I never corrected him but made a mental note not to trust the guy.
This is a handy tool, but I wish it supported edge snapping. If you inspect the generated LaTeX it doesn't actually link up the FSM states, it just anchors them to raw TikZ coordinates.
Maciej Bendkowski has some related work [1] on generating random lambda terms, but was unable to overcome what he calls the asymptotic sparsity problem:
Sampling simply-typed terms seems notoriously more challenging than sampling closed ones. Even rejection sampling, whenever applicable, admits serious limitations due to the imminent asymptotic sparsity problem — asymptotically almost no term, be it either plain or closed, is at the same time (simply) typeable. [...] Asymptotic sparsity of simply-typed λ-terms is an impenetrable barrier to rejection sampling techniques. As the term size tends to infinity, so does the induced rejection overhead. In order to postpone this inevitable obstacle, it is possible to use dedicated mechanisms interrupting the sampler as soon as it is clear that the partially generated term cannot be extended to a typeable one. The current state-of-the-art samplers take this approach, combining Boltzmann models with modern logic programming execution engines backed by highly-optimised unification algorithms. Nonetheless, even with these sophisticated optimisations, such samplers are not likely to generate terms of sizes larger than one hundred.
I would be curious to see a more rigorous analysis of the sample complexity of generating well-typed expressions in, e.g., the STLC. Maybe there is a way to avoid or reduce the rejection rate before evaluation.
The trick is not just synthesizing valid functions, but doing so in a parallel communication-free manner, without compromising soundness or completeness. You want to massively scale up a discrete sampler without replacement. One very efficient way of doing this is by constructing an explicit bijection from the sample space to the integers, sampling integers, then decoding them into programs.
While this technique enjoys certain advantages, i.e., it is embarrassingly parallelizable and guaranteed to enumerate distinct solutions with a bounded delay, it also somewhat unnatural. By flattening the distribution onto the integers a la Gödel numbering, it destroys locality, does not play well with incremental decoding methods (left-to-right is currently en vogue in generative language modeling), and will fail if the sample space is uncountable.
Another key step is reducing symmetries in your sample space by quotienting it somehow (e.g., by α-equivalence). The author seems to be invoking some kind of equivalence relation by “superposition”, but the technical details here are a little fuzzy.
This problem is also closely related to model counting in the CSP literature, so a practical speedup could lead to improvements on a lot of interesting downstream benchmarks.
In general, the problem of program induction from input-output examples is not well-posed, so specialized solvers that can make stronger assumptions will usually have an advantage on domain-specific benchmarks. Most existing program synthesizers do not satisfy all of these desiderata (e.g., soundness, completeness, naturalness, incrementality).
>> The trick is not just synthesizing valid functions, but doing so in a parallel communication-free manner, without compromising soundness or completeness.
Right! A great way to do this is to learn a program by using it to prove the training examples while it is being learned. A very cool ability that some systems of the new wave of Inductive Logic Programming can pull off, but probably nothing else can far as I can tell.
>> There are quite a few publications that explore the concept of generating programs, either using typed or untyped functional languages.
That's Inductive Functional Programming (IFP), a kind of Inductive Programming that also includes Inductive Logic Programming (ILP). The canonical example of IFP is Magic Haskeller:
One of the DreamCoder papers describes Inductive Programming as a form of weakly supervised learning, in the sense that such systems learn to generate programs not from examples of programs, but from examples of the target programs' beuav908rs, i.e. their inputs and outputs. By contrast LLMs or slightly older neural program synthesis systems are trained on examples that consist of pairs of (programming-task, program-solving-the-task).
Another way to see the difference between Inductive Programming systems and conventional machine learning systems used for program synthesis is that Inductive Programming systems learn by solving problems rather than from observing solutions.
The advantage is that, in this way, we can learn programs that we don't know how to write (because we don't have to generate examples of such programs) whereas with conventional machine learning we can only generate programs like the ones the system's been trained on before.
Another advantage is that it's much easier to generate examples. For instance, if I want to learn a program that reverses a list, I give some examples of lists and their reverse, e.g. reverse([a,b,c],[c,b,a]) and reverse([1,2,3],[3,2,1]) whereas e.g. an LLM must be trained on explicit examples of list-reversing programs; like, their source code.
IFP and ILP systems are also very sample efficient, so they only need a handful of examples, often just one, whereas neural net-based systems may need millions (no exaggeration- can give a ref if needed).
The disadvantage is that learning a program usually (but not always - see Louise, above) implies searching a very large combinatorial space and that can get very expensive, very, very fast. But, there are ways around that.
Knowin ILP at all, let alone well, is so rare that I totally misread your comment.
I'm one of the last purely symbolic hold-outs in ILP I guess. But if you're interested in recent neurosymbolic work using MIL this is some recent work from my colleagues:
There's usually a DL part (the neural network), welded together with a classical AI algorithm, e.g. Monte Carlo Tree Search, or some kind of theorem prover.
The symbolic part is the MCTS and/or theorem prover. DL is deep learning, i.e. the multilayered neural network. Neurosymbolic approaches form a significant branch of current machine learning. You can read up on all of it if you're actually curious and asking all this in good faith, but I suspect you're not.
I did some work on this about a decade ago, using RL on STLC, and that was the same problem I faced. It’s too bad so few well typed expression trees are very useful programs.
{kind=link}